Foundation models have transformed vision and language processing by providing rich, reusable representations that transfer across diverse tasks. Sheet music, as a visual encoding of musical language, has lacked such a domain-specific backbone — until now.
How MuSViT works
MuSViT uses a ViT architecture with 12 Transformer layers. Input images are split into 16x16 patches projected to 768-dimensional embeddings. 2D sinusoidal positional encodings explicitly capture vertical position — critical for reading staff lines and pitch.
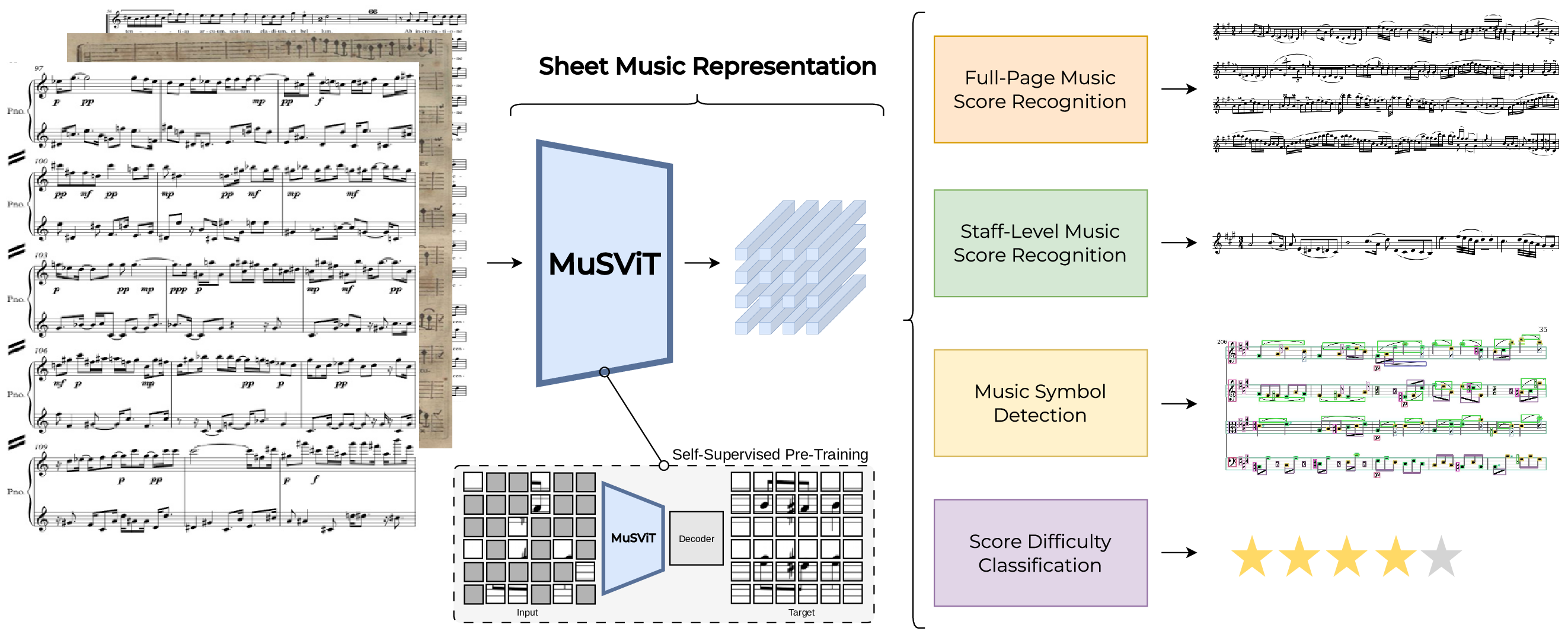
Four downstream tasks
Metrics: SER ↓
Metrics: SER ↓
Metrics: mAP, w-mAP ↑
Metrics: Acc0, Acc1 ↑
Summary of contributions
- Public release of MuSViT — the first vision foundation model for sheet music, pre-trained via MAE on 9.7M IMSLP pages through a two-stage synthetic-to-real curriculum. Model weights, pre-training code, and evaluation scripts are publicly released.
- Comprehensive evaluation across four representative downstream tasks under linear probing and fine-tuning. MuSViT outperforms all general-purpose encoders under linear probing, and surpasses task-specific SoTA on three of four tasks under fine-tuning.
- Embedding-transcription consistency analysis providing direct evidence that MuSViT representations correlate with symbolic musical content (ρ > 0.6), while all general-purpose encoders yield anti-correlated embeddings.
If you use MuSViT, please cite the ECCV 2026 paper.
@inproceedings{penarrubia2026musvit,
title = {MuSViT: A Foundation Vision Model for Sheet Music Representation},
author = {Penarrubia, Carlos and Rios-Vila, Antonio and Fuentes-Martinez, Eliseo
and Martinez-Sevilla, Juan C. and Castellanos, Francisco J. and
Alfaro-Contreras, Maria and Calvo-Zaragoza, Jorge},
booktitle = {European Conference on Computer Vision (ECCV)},
year = {2026}
}The authors gratefully acknowledge Edward Guo, on behalf of IMSLP/Petrucci Music Library, for providing access to the data used to train the models.
This publication is part of the LEMUR project PID2023-148259NB-I00, funded by MICIU/AEI/10.13039/501100011033 and by ERDF/EU. The first author is supported by the University of Alicante through the FPU Program (UAFPU22-19). The third author is supported by a predoctoral contract associated with the LEMUR project. The fourth author is supported by a predoctoral contract from grant CISEJI/2023/9 "Programa para el apoyo a personas investigadoras con talento (Plan GenT) de la Generalitat Valenciana".